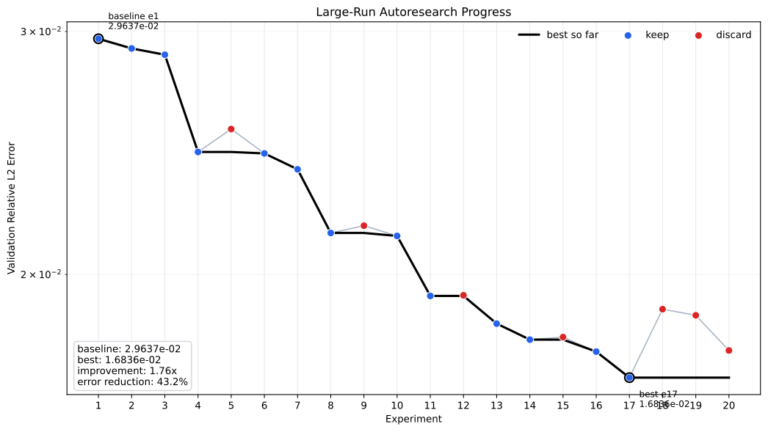
This work was carried out primarily by Atharva Hans, with the help of Alex Alberts. Max and I are mostly observing.
Replicating a scientific paper is an important task. Every researcher has to grind through this process, often many times. I have done it repeatedly while creating educational activities for my courses. I also ask graduate students to do it to develop their mathematical and coding skills. Every time we encounter a new dataset to analyze, we typically start by trying an existing method. And every time we develop a new method, we compare it against the state of the art.
Sometimes, replicating a paper is relatively straightforward, especially if the authors carefully include all required information about parameters and hyperparameters and also provide the code. Even then, the process takes time. First, you have to read and understand the paper. Depending on your familiarity with the literature, this may take anywhere from a few days to an entire month. You may also need to set up your computational environment, download and understand the data, run cluster jobs, move data around, generate figures, and so on.
More often than not, however, something is missing. The code may not be available. You may have to write it yourself, debug it, and verify it with synthetic examples. Important details may also be absent from the paper. For example, the authors may say that they performed “hyperparameter optimization” without specifying how. Or the paper may rely on methods you are not familiar with, forcing you to read additional papers before you can even begin implementing the approach.
Using AI agents to replicate papers is, therefore, an intriguing use case. Tools like Codex, Claude Code, and OpenClaw have already reached a stage where they can attempt such tasks. We have started putting them to the test.
The basic setup
We have an old Mac Pro machine with Homebrew installed. We also installed LaTeX for generating reports. We have a ChatGPT Pro subscription ($200/month). We run the Codex app for macOS with GPT-5.3-Codex using “Medium” thinking, and we give it “Full access.”
Keeping track of what it does
We set up SSH keys so the system can access our lab’s GitHub repository (PredictiveScienceLab). We launch the Codex app inside an existing repository. Thankfully, Codex has not yet escaped and started deleting our prior work…
Accessing high-performance computing clusters
We configured SSH keys that allow Codex to access Purdue’s high-performance computing clusters (Gautschi and Bell) to run code on both GPUs and CPUs. We created a cluster skill that teaches it how to transfer data, load modules, submit SLURM jobs, and monitor them. Here are the first few line of the kill:
---
name: cluster-slurm
description: Deterministic SLURM orchestration over SSH with profile-based cluster routing, strict profile-managed environments, run ledgers, and artifact retrieval. Use when users ask to run heavy compute, submit SLURM jobs, monitor queue status/logs, or download outputs from any configured SLURM cluster.
---
# Cluster SLURM
Use this skill for cluster-first execution on configured SLURM clusters. Keep orchestration local and compute on cluster.
## First-run setup
1. Initialize and configure in one pass:
```bash
python3 ~/.codex/skills/cluster-slurm/scripts/cluster_slurm.py setup --cluster gautschi
```
This first setup is interactive by design and must be completed with direct user input.
Setup now prompts for:
- SSH target
- environment setup mode:
- setup your own environment (`custom`) (use default custom setup commands, or provide overrides)
- set up a new environment that will be used starting next run (`bootstrap-env`)
...
Note that the skill also has some scripts that it can call.